Previously, I also obtained my Bachelor’s and Master’s in Computer Science at RWTH University.
My master’s thesis led to my first (joint) publication on passenger prediction in public transport, but my focus has since shifted toward graph signal processing, algebraic topology, and higher-order networks.
In that area, I am proud to report that our paper Representing Edge Flows on Graphs via Sparse Cell Complexes received the Best Paper award at the 2023 Learning on Graphs Conference.
In connection with my research, I have also published or contributed to the following software packages:
🌼 CellFlower infers 2-cells from edge flows (Implementation of Representing Edge Flows via Sparse Cell Complexes)
🦝 PyRaCCooN generates random cell complexes & approximately counts simple cycles on a graph (Implementation of Random Abstract Cell Complexes)
TopoX (software engineering / refactoring and reviewing of PRs)
2024-10-22SIAM MDS in Atlanta, Minisymposium ‘Machine Learning on Graphs for Physical Sciences and Data Analysis’: Invited Talk on Representing Edge Flows on Graphs via Sparse Cell Complexes (see Publications).
2024-06-26Graph Signal Processing Workshop in Delft: Contributed Talk on Representing Edge Flows on Graphs via Sparse Cell Complexes (see Publications).
Cell complexes (CCs) are a higher-order network model deeply rooted in algebraic topology that has gained interest in signal processing and network science recently. However, while the processing of signals supported on CCs can be described in terms of easily-accessible algebraic or combinatorial notions, the commonly presented definition of CCs is grounded in abstract concepts from topology and remains disconnected from the signal processing methods developed for CCs. In this paper, we aim to bridge this gap by providing a simplified definition of CCs that is accessible to a wider audience and can be used in practical applications. Specifically, we first introduce a simplified notion of abstract regular cell complexes (ARCCs). These ARCCs only rely on notions from algebra and can be shown to be equivalent to regular cell complexes for most practical applications. Second, using this new definition we provide an accessible introduction to (abstract) cell complexes from a perspective of network science and signal processing. Furthermore, as many practical applications work with CCs of dimension 2 and below, we provide an even simpler definition for this case that significantly simplifies understanding and working with CCs in practice.
We define a model for random (abstract) cell complexes (CCs), similiar to the well-known Erdős-Rényi model for graphs and its extensions for simplicial complexes. To build a random cell complex, we first draw from an Erdős-Rényi graph, and consecutively augment the graph with cells for each dimension with a specified probability. As the number of possible cells increases combinatorially -- e.g., 2-cells can be represented as cycles, or permutations -- we derive an approximate sampling algorithm for this model limited to two-dimensional abstract cell complexes. As a basis for this algorithm, we first introduce a spanning-tree-based method that samples simple cycles and allows the efficient approximation of various properties, most notably the probability of occurence of a given cycle. This approximation is of independent interest as it enables the approximation of a wide variety of cycle-related graph statistics using importance sampling. We use this to approximate the number of cycles of a given length on a graph, allowing us to calculate the sampling probability to arrive at a desired expected number of sampled 2-cells. The probability approximation also trivially leads to a sampling algorithm for 2-cells with a desired sampling probability. We provide some initial analysis into the properties of random CCs drawn from this model. We further showcase practical applications for our random CCs as null models, and in the context of (random) liftings of graphs to cell complexes. The cycle sampling, cycle count estimation, and combined cell sampling algorithms are available in the package `py-raccoon` on PyPI.
We consider the following inference problem: Given a set of edge-flow signals observed on a graph, lift the graph to a cell complex, such that the observed edge-flow signals can be represented as a sparse combination of gradient and curl flows on the cell complex. Specifically, we aim to augment the observed graph by a set of 2-cells (polygons encircled by closed, non-intersecting paths), such that the eigenvectors of the Hodge Laplacian of the associated cell complex provide a sparse, interpretable representation of the observed edge flows on the graph. As it has been shown that the general problem is NP-hard in prior work, we here develop a novel matrix-factorization-based heuristic to solve the problem. Using computational experiments, we demonstrate that our new approach is significantly less computationally expensive than prior heuristics, while achieving only marginally worse performance in most settings. In fact, we find that for specifically noisy settings, our new approach outperforms the previous state of the art in both solution quality and computational speed.
In The Second Learning on Graphs Conference,
2023.
Obtaining sparse, interpretable representations of observable data is crucial in many machine learning and signal processing tasks. For data representing flows along the edges of a graph, an intuitively interpretable way to obtain such representations is to lift the graph structure to a simplicial complex: The eigenvectors of the associated Hodge-Laplacian, respectively the incidence matrices of the corresponding simplicial complex then induce a Hodge decomposition, which can be used to represent the observed data in terms of gradient, curl, and harmonic flows. In this paper, we generalize this approach to cellular complexes and introduce the cell inference optimization problem, i.e., the problem of augmenting the observed graph by a set of cells, such that the eigenvectors of the associated Hodge Laplacian provide a sparse, interpretable representation of the observed edge flows on the graph. We show that this problem is NP-hard and introduce an efficient approximation algorithm for its solution. Experiments on real-world and synthetic data demonstrate that our algorithm outperforms current state-of-the-art methods while being computationally efficient.
In Asilomar Conference on Signals, Systems, and Computers (in press),
2024.
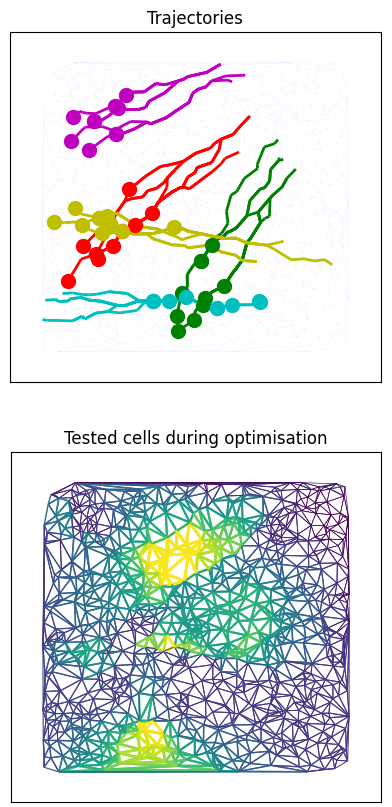
We consider the problem of classifying trajectories on a discrete or discretised 2-dimensional manifold modelled by a simplicial complex. Previous works have proposed to project the trajectories into the harmonic eigenspace of the Hodge Laplacian, and then cluster the resulting embeddings. However, if the considered space has vanishing homology (i.e., no "holes"), then the harmonic space of the 1-Hodge Laplacian is trivial and thus the approach fails. Here we propose to view this issue akin to a sensor placement problem and present an algorithm that aims to learn "optimal holes" to distinguish a set of given trajectory classes. Specifically, given a set of labelled trajectories, which we interpret as edge-flows on the underlying simplicial complex, we search for 2-simplices whose deletion results in an optimal separation of the trajectory labels according to the corresponding spectral embedding of the trajectories into the harmonic space. Finally, we generalise this approach to the unsupervised setting.
In IEEE Open Journal of Intelligent Transportation Systems,
2023.
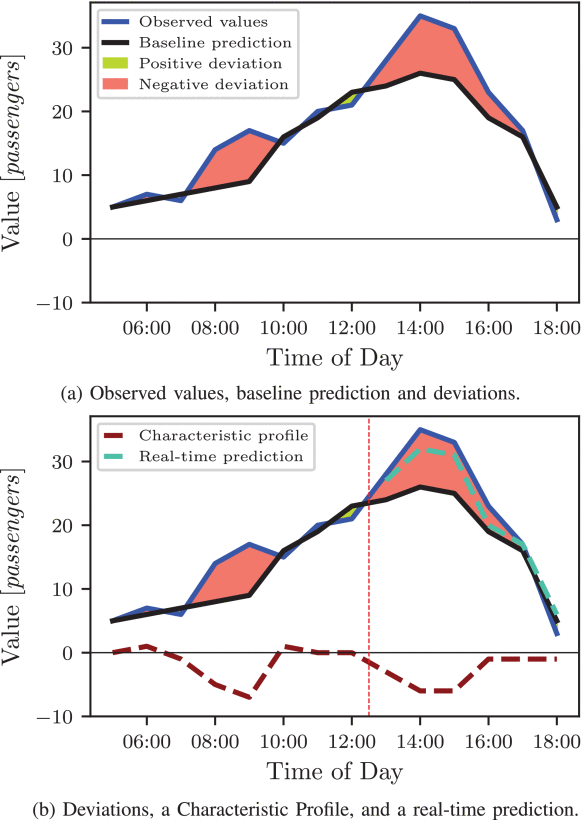
Good public transport occupancy predictions are important for both passengers (to avoid crowded vehicles) and operating companies (to intervene with dispositive actions, hereby increasing the service quality). In this paper, we present a novel approach to improve the real-time prediction of passenger numbers. It combines a day-ahead prediction made using SARIMA with a real-time detection of characteristic deviation profiles. In our experiments with data from Germany, the proposed model outperforms artificial neural networks when only little data is available or the prediction happens with larger lead times than 90 minutes. It also has the inherent advantage of being faster to train and explainable in all steps.
Cite Don't be Afraid of Cell Complexes! An Introduction from an Applied Perspective
@misc{hoppe2025cellcomplexes, title={Don't be Afraid of Cell Complexes! An Introduction from an Applied Perspective}, author={Josef Hoppe and Vincent P. Grande and Michael T. Schaub}, year={2025}, eprint={2506.09726}, archivePrefix={arXiv}, primaryClass={eess.SP}, url={https://arxiv.org/abs/2506.09726}, }
Cite Random Abstract Cell Complexes
@misc{hoppe2024random, title={Random Abstract Cell Complexes}, author={Josef Hoppe and Michael T. Schaub}, year={2024}, eprint={2406.01999}, archivePrefix={arXiv}, primaryClass={cs.DS} }
Cite Faster Inference of Cell Complexes from Flows via Matrix Factorization
@INPROCEEDINGS{11226659,
author={Spreuer, Til and Hoppe, Josef and Schaub, Michael T.},
booktitle={2025 33rd European Signal Processing Conference (EUSIPCO)},
title={Faster Inference of Cell Complexes from Flows via Matrix Factorization},
year={2025},
volume={},
number={},
pages={2487-2491},
keywords={Laplace equations;Scalability;Europe;Signal processing;Approximation error;Noise measurement;Sparse matrices;Matrix decomposition;Iterative methods;Synthetic data;Topological signal processing;graph signal processing;cell inference;cell complex;edge flows},
doi={10.23919/EUSIPCO63237.2025.11226659}}
Cite Representing Edge Flows on Graphs via Sparse Cell Complexes
@InProceedings{hoppe2023representing,
title = {Representing Edge Flows on Graphs via Sparse Cell Complexes},
author = {Hoppe, Josef and Schaub, Michael T},
booktitle = {Proceedings of the Second Learning on Graphs Conference},
pages = {1:1--1:22},
year = {2024},
editor = {Villar, Soledad and Chamberlain, Benjamin},
volume = {231},
series = {Proceedings of Machine Learning Research},
month = {27--30 Nov},
publisher = {PMLR},
pdf = {https://proceedings.mlr.press/v231/hoppe24a/hoppe24a.pdf},
url = {https://proceedings.mlr.press/v231/hoppe24a.html},
}
Cite Topological Trajectory Classification and Landmark Inference on Simplicial Complexes
@inproceedings{grande2024topological,
author={Grande, Vincent P. and Hoppe, Josef and Frantzen, Florian and Schaub, Michael T.},
booktitle={2024 58th Asilomar Conference on Signals, Systems, and Computers},
title={Topological Trajectory Classification and Landmark Inference on Simplicial Complexes},
year={2024}, volume={}, number={}, pages={44-48}, doi={10.1109/IEEECONF60004.2024.10942887}
}
Cite Improving the Prediction of Passenger Numbers in Public Transit Networks by Combining Short-Term Forecasts With Real-Time Occupancy Data
@ARTICLE{10057448,
author={Hoppe, Josef and Schwinger, Felix and Haeger, Henrik and Wernz, Jonas and Jarke, Matthias},
journal={IEEE Open Journal of Intelligent Transportation Systems},
title={Improving the Prediction of Passenger Numbers in Public Transit Networks by Combining Short-Term Forecasts With Real-Time Occupancy Data},
year={2023},
volume={4},
number={},
pages={153-174},
doi={10.1109/OJITS.2023.3251564}}